Many professional scraping services exist that offer data extraction services to their clients. More often than not, those services attempt to camouflage that they are bots. Sometimes even professional services make mistakes though.
My intention with this blog post is not to diminish and look down on the work that those services have put into their products. I just want to demonstrate that there are a plethora of ways to detect the automated nature of their traffic.
In my opinion, it is much harder to create a stealthy scraping service than to detect it: For detection, you only need to find one single anomaly. To remain stealthy, you must be perfect. Therefore, a resilient and stealthy scraping service is very hard to find. I hope those services can make use of some of my resarch provdided for free here.
General Strategy: The bot detection site bot.incolumitas.com was used as a scraping target with all scraping services listed below. For Luminati.io I had to mount heavy machinery to detect their data collector as bot. I always used the JavaScript rendering option from the scraping services listed below (thus using real browsers).
TL;DR
-
Luminati.io:
navigator.platformisLinux x86_64in Web Worker and iframe contexts compared toWin32in the normalwindow.navigator.platformproperty. In some cases, the TCP/IP fingerprint doesn't look like a Windows NT 10.0 fingerprint, even though the User-Agent claims it. -
ScrapingBee: The browser fingerprint is identical for all their scraping instances.
navigator.platformis still set toLinux x86_64although the User-Agent is either Intel Mac OS X or Windows NT. -
scraperapi.com: The same issue here, the browser fingerprint is identical for all their scrapers. Weird timezone browser settings of
Etc/Unknown, strange default screen dimensions, no WebGL vendor renderer information. -
scrapingrobot.com: Inconsistent screen dimensions. No plugin information in
navigator.plugins. No multimedia devices innavigator.mediaDevices. -
scrapfly.io: Inconsistent User-Agent in the HTTP header and in
navigator.userAgent. All their scrapers use always the same video card of ANGLE (NVIDIA GeForce GTX 660 Direct3D9Ex vs_3_0 ps_3_0). No plugin information innavigator.plugins. No multimedia devices innavigator.mediaDevices.
Detecting Luminati.io
Luminati is arguably one of the best scraping / proxying services out there, albeit one of the most expensive.
I don't like to admit it, because I don't really dig their business strategy, but from all of the researched scraping businesses, they are by far the best.
I heavily suspect that they actually use the real browsers from the users that have installed the hola browser extension for scraping. I cannot explain how else they manage to create such a convincingly real browser profile. Edit: Found some concrete issues that suggest that the above statement is no longer the case.
For a long time, Luminati only offered proxies, but they started to offer data extraction tools using real web browsers.
With Luminati, you can use proxies like that:
curl --proxy zproxy.lum-superproxy.io:22225 --proxy-user lum-customer-xxx:yyy "https://bot.incolumitas.com/"
But we are more interested in their custom data collector which uses a real browser to proxy their requests.
We create the following data collector:
navigate('https://bot.incolumitas.com/');
wait_for_text('#ja3', 'ja3_digest');
collect({
url: location.href,
});
After scraping the bot detection site for a couple of times, those are the fingerprints we manage to obtain:
| # | ip | user agent | browser fingerprint | ja3 fingerprint | p0f fingerprint | canvas fingerprint | WebGL fingerprint |
|---|---|---|---|---|---|---|---|
| 1 | 11.22.33.44 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.83 Safari/537.36 | ff85adf22012f400f5333f54ffebc916 | b32309a26951912be7dba376398abc3b / 7f805430de1e7d98b1de033adb58cf46 | Linux 2.2.x-3.x [generic] | DAC6F11B | 301740 |
| 2 | 11.22.33.55 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.83 Safari/537.36 | 68a9ea61c7ae62f1d9d2c348c1823a2c | b32309a26951912be7dba376398abc3b / 7f805430de1e7d98b1de033adb58cf46 | Linux 2.2.x-3.x [generic] | DA9F01B9 | 301740 |
| 3 | 11.22.33.66 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 | ffe31d567bd285ba340797681a136cc3 | 7f805430de1e7d98b1de033adb58cf46 / b32309a26951912be7dba376398abc3b | Linux 2.2.x-3.x [generic] | 6CE02F78 | 301740 |
| 4 | 11.22.33.77 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 | a00f02fed04ef645c1abb335dfe3e12f | 7f805430de1e7d98b1de033adb58cf46 / b32309a26951912be7dba376398abc3b | Linux 2.2.x-3.x [generic] | 6FDC3774 | 301740 |
| 5 | 11.22.33.88 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 | c0d70db11fc439a78865a0f89f7fa65e | b32309a26951912be7dba376398abc3b / 7f805430de1e7d98b1de033adb58cf46 | Windows NT kernel [generic] | D40672D6 | 301740 |
| 6 | 11.22.33.99 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 | b631bc196165e8f5931b0388a20eb69f | 7f805430de1e7d98b1de033adb58cf46 / b32309a26951912be7dba376398abc3b | Linux 2.2.x-3.x [generic] | 5D10FDE8 | 301740 |
After a thorough analysis, I have to admit that Luminati.io is doing many things extremely well.
The WebGL fingerprint (which is shortened in the table) is inaccurate. It does not say much that it is always identical. I have the same WebGL fingerprint on my Android phone. The same applies to the TLS fingerprint. There is not enough entropy in this TLS fingerprint to deduce a statement.
The canvas fingerprint and the browser fingerprint do change with every new scraping instance. Just as expected.
The only curious thing is the Linux OS that was detected by p0f. But I do not trust this OS detection feature from p0f all that much. p0f seems quite old and is not really maintained since years. It doesn't event detect Linux kernels newer than 3.x versions.
Maybe we have to dig a bit deeper regarding OS fingerprinting on a TCP/IP level.
Satori.py looks like a good tool for it with an extensive and up to date database. It's written in easy to understand Python and this gives me enough freedom to hack my own logic into it if needed. p0f seems a bit more complicated and not so fast for quick changes in comparison.
So the strategy looks like the following:
- We collect several Luminati.io TCP/IP network captures and check the RAW TCP/IP signature that we obtain.
- Then we check if this signature is significantly different from the User Agent that Luminati claims to be.
After trying for a bit with Satori.py I realized that the tool was a huge mess and I ended up creating my own TCP/IP fingerprinting tool.
I compiled my own TCP/IP fingerprint database and started to compare the Luminati data collector against it.
In almost all cases I got something like this:
{'score': '9.5/9.5', 'os': 'Windows NT 10.0; Win64; x64'}
Luminati claims in it's User-Agent that it is Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 and in almost all cases, the TCP/IP fingerprint agrees with that.
I had only one case where I got a TCP/IP fingerprint which I could not properly identify.
[{'score': '6/9.5', 'os': 'Macintosh; Intel Mac OS X 11_2_3'}, {'score': '6/9.5', 'os': 'X11; Linux x86_64'}, {'score': '6/9.5', 'os': 'Windows NT 10.0; Win64; x64'}, {'score': '5/9.5', 'os': 'Windows NT 6.1; Win64; x64; rv:87.0'}]
In that case, I have no exact match in my database. So even if Luminati is lying here, then in only 1/10 cases Luminati.io bots are detectable with TCP/IP fingerprinting. That is by far a too weak signal.
So there must be good way to detect that the traffic coming from Luminati.io is not humanly generated and thus not organic.
Of course we could say that the lack of human UI interaction events is suspicious. But their bot only stays on the website for a few seconds. Opening a tab and not interacting with the page could also be the result of human behavior.
Maybe Luminati bot traffic is detectable by measuring latency and RTT's. After all, when my theory is correct, they need to route traffic somehow like that:
[Luminati data collector] => [Luminati hola browser extension user] => [bot.incolumitas.com] => and all the way back.
Maybe this information helps us to to something. However, I don't have a clear plan here.
What else is there to try?
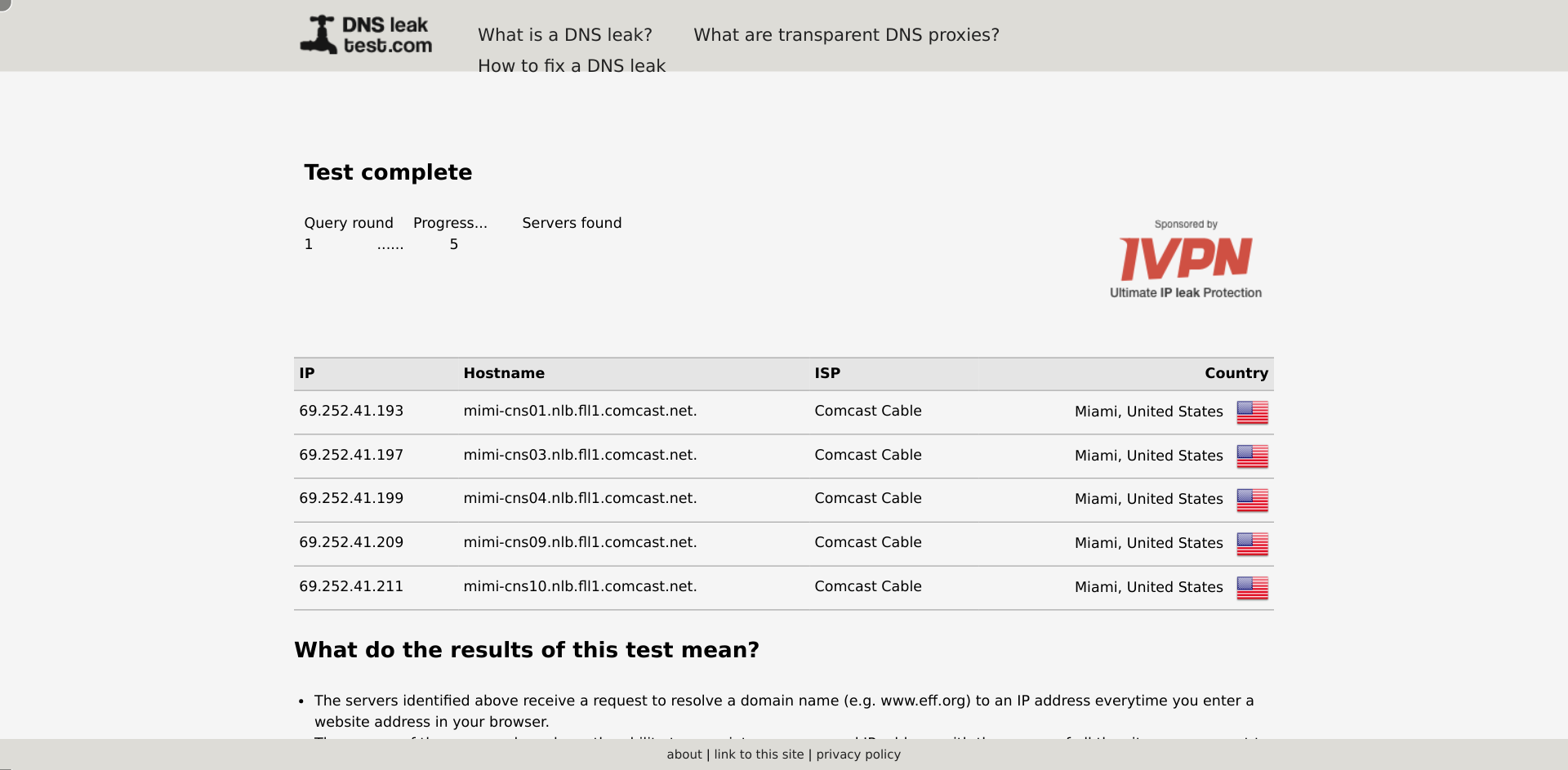
I tried to see what DNS servers the data collectors from Luminati.io are using:
navigate('https://www.dnsleaktest.com/');
click('input.standard')
wait_visible('#results tbody tr:nth-of-type(2)', {timeout: 30000});
wait_for_text('th.align-right', 'Country');
wait_visible('td > img.ispcountry');
collect({
url: location.href,
});
But it is all perfect:
As a next step I looked if the data collectors supported WebSockets:
navigate('https://websocketstest.com/');
wait_visible('#results_line');
collect({
url: location.href,
});

Detecting Luminati.io with the help of creepJS
Now I decided to see what creepJS would say about the Luminati.io data collectors:
navigate('https://abrahamjuliot.github.io/creepjs/');
wait_visible('#headless-detection-results');
wait_for_text('.headless-rating', 'detected');
wait('#signature-input');
scroll_to('#fingerprint-data > div:nth-child(13)');
click('#toggle-open-creep-lies');
click('#toggle-open-creep-trash');
collect({
url: location.href,
});
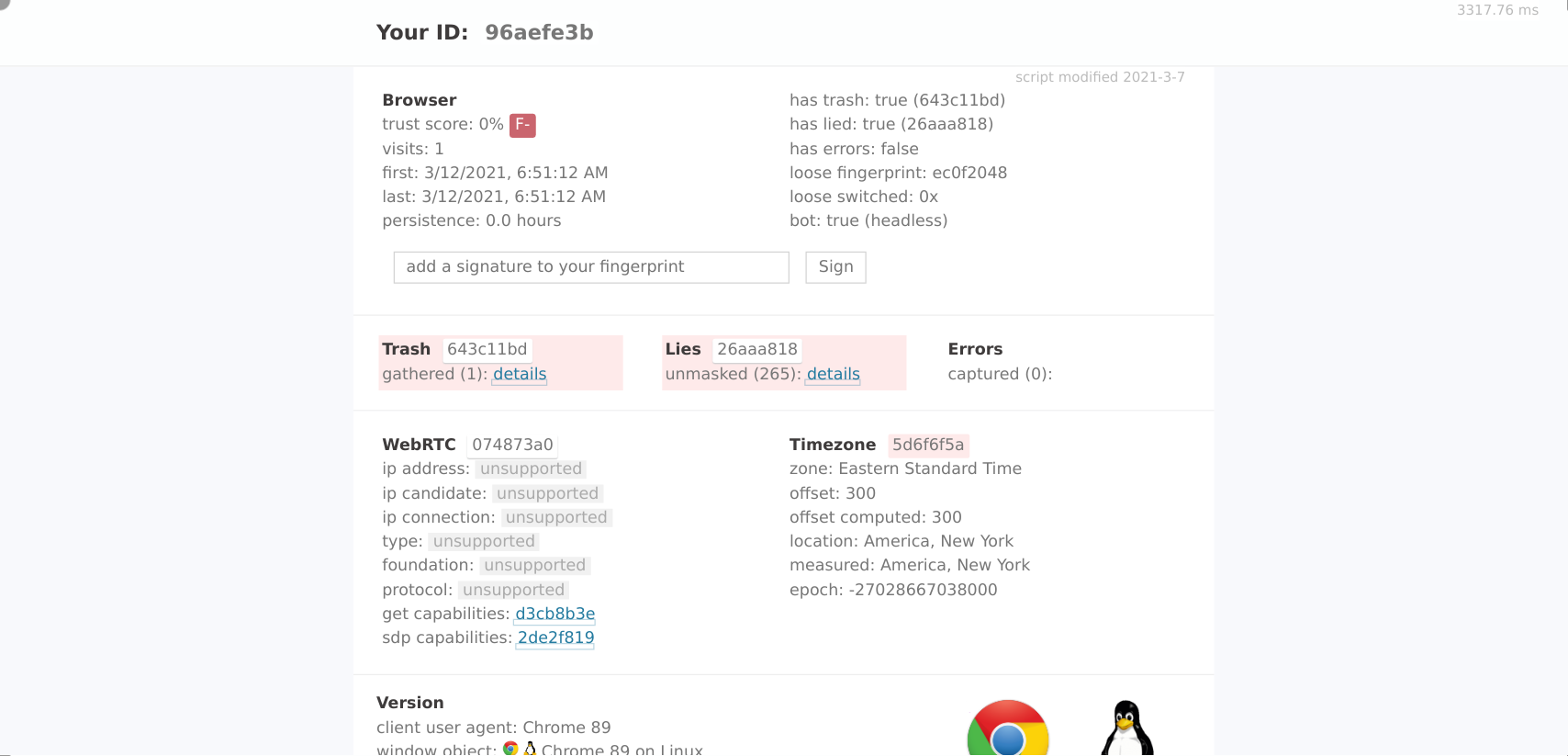
As you can see, the CreepJS bot detection tool gives Luminati Data Collectors the worst rating possible: F-
But why exactly?
When digging into the results, I found the following inconsistencies with Web Workers:
- The Web Workers have a inconsistent
navigator.platformcompared to the normalnavigator.platform. In the Web Worker context, it is set to"platform": "Linux x86_64". - The property
navigator.hardwareConcurrencyis 2 compared to 4 in the normal window browser context - In General: the
navigatorproperty in Web Workers is different in many properties compared to the normalwindow.navigatorproperty. This should not be the case if the browser has not been tampered with!
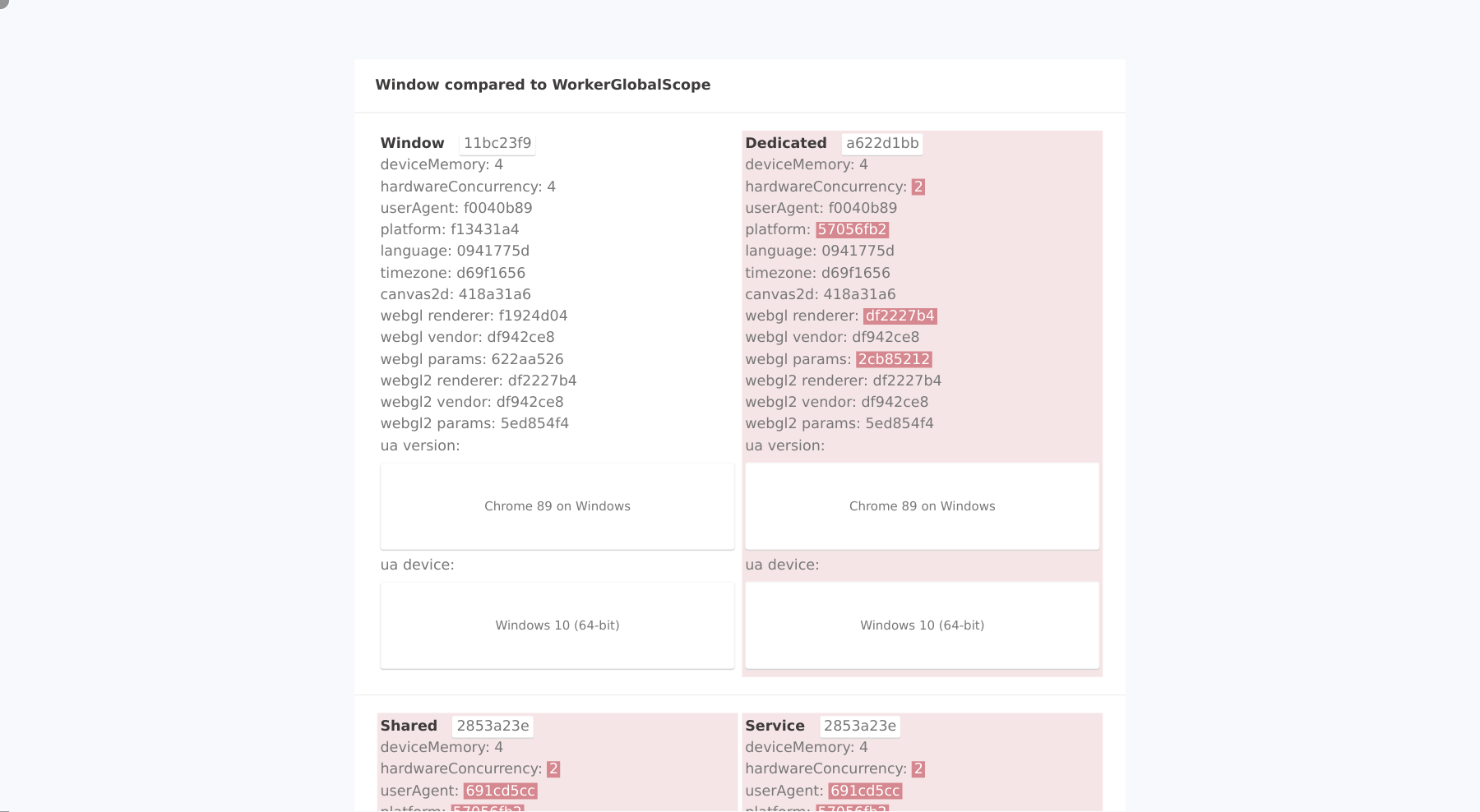
When visiting the CreepJS Web Worker detection site with the Luminati Data Collector tool with the following sraping script
navigate('https://abrahamjuliot.github.io/creepjs/tests/workers.html');
wait_for_text('#fingerprint-data', 'ua device:');
scroll_to('#fingerprint-data > div:nth-child(3)');
collect({
url: location.href,
});
we get the following results
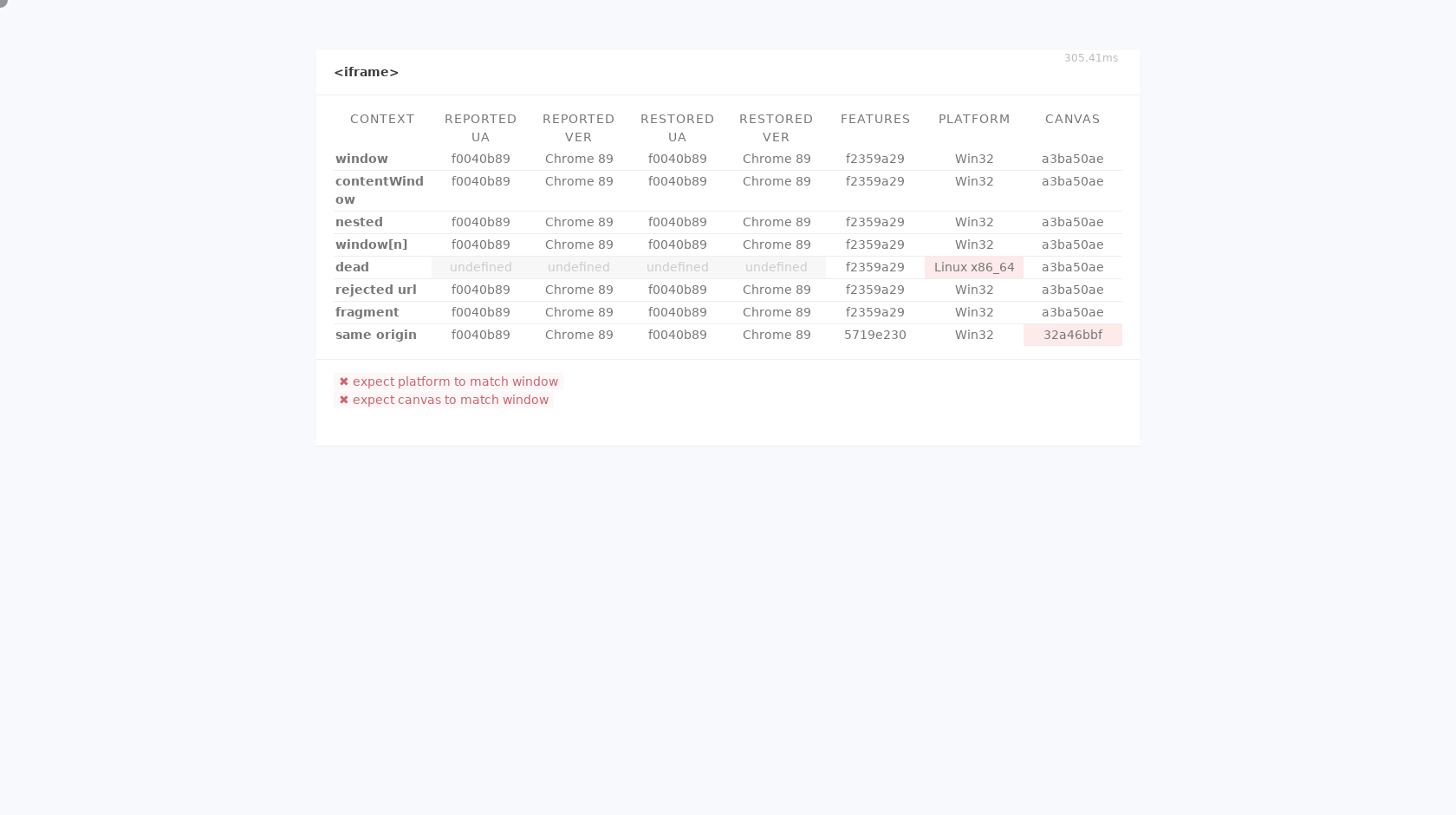
Another issue with the Luminati.io data collector is that it fails to spoof the navigator.platform property in iframes. The corresponding creepJS iframe test illustrates the issues:
In conclusion, I can say that Luminati.io is doing a very good job in hiding that their data collector is an automated bot and not a real human being.
However, they forgot to spoof the navigator.platform property in Web Worker and iframe contexts.
No real Windows 10 Chrome Browser has a navigator.platform of Win32 in the normal window object but a value of Linux x86_64 in iframes and Web Worker contexts...
Detecting ScrapingBee
I collected several samples from scrapingbee. I used the following API call:
curl "https://app.scrapingbee.com/api/v1/?api_key={API_KEY}&url=https%3A%2F%2Fbot.incolumitas.com%2F&wait=4000&block_ads=false&block_resources=false"
Here are some extracted criteria from the seven samples:
| # | ip | user agent | browser fingerprint | tls fingerprint | tcp/ip fingerprint | |
|---|---|---|---|---|---|---|
| 1 | 107.152.210.73 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | 7f805430de1e7d98b1de033adb58cf46 | Linux 3.x [generic] | |
| 2 | 107.173.246.155 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | b32309a26951912be7dba376398abc3b | Linux 3.x [generic] | |
| 3 | 209.127.110.235 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | - | Linux 2.2.x-3.x [generic] | |
| 4 | 104.144.180.182 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | b32309a26951912be7dba376398abc3b | Linux 3.x [generic] | |
| 5 | 209.127.98.44 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | - | Linux 2.2.x-3.x [generic] | |
| 6 | 209.127.105.200 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | - | Linux 2.2.x-3.x [generic] | |
| 7 | 107.175.157.30 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | b32309a26951912be7dba376398abc3b | Linux 3.x [generic] | |
| 8 | 186.179.14.119 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 | b11a52c168016c4ba71b5275117ccf27 | - | Linux 3.11 and newer |
As you can see, the browser fingerprint is in every case the same: b11a52c168016c4ba71b5275117ccf27
This is very bad. This means that it is possible to detect user agents with the above fingerprint to be a ScrapingBee bot with relatively high likelihood.
But they made more mistakes:
For example they set the user agent to either
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36
- Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
but they forget to spoof the navigator.platform property accordingly. It is still set to "platform": "Linux x86_64". Obviously, that is very suspicious and would get flagged by many bot detection programs.
One issue could be that their browser don't seem to support any multimedia devices:
"multimediaDevices": {
"speakers": 0,
"micros": 0,
"webcams": 0
}
This is usually very uncommon for normal devices. They at least support one multimedia device.
Detecting scraperapi.com
This is another commercial scraping service. Their scrapers also exhibit some weird behavior.
When scraping with the scraperapi.com API for five times with the following API call:
curl "http://api.scraperapi.com/?api_key={{API_KEY}}&url=http://bot.incolumitas.com/&render=true"
we obtain the following fingerprints:
| # | user agent | browser fingerprint | ja3 fingerprint | canvas fingerprint |
|---|---|---|---|---|
| 1 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 | 792ce97b0295f6f9f0d89fe974371a84 | b32309a26951912be7dba376398abc3b | E5063313 |
| 2 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 | 792ce97b0295f6f9f0d89fe974371a84 | b32309a26951912be7dba376398abc3b | E5063313 |
| 3 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 | 792ce97b0295f6f9f0d89fe974371a84 | b32309a26951912be7dba376398abc3b | E5063313 |
| 4 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 | 792ce97b0295f6f9f0d89fe974371a84 | b32309a26951912be7dba376398abc3b | E5063313 |
| 5 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 | 792ce97b0295f6f9f0d89fe974371a84 | b32309a26951912be7dba376398abc3b | E5063313 |
It is quite obvious that it is very bad that every browser fingerprint is exactly the same. This means that is possible to state that a website is being scraped whenever a visitor uses a browser fingerprint of 792ce97b0295f6f9f0d89fe974371a84.
Some other issues were:
Their scraping browsers have the timezone set to Etc/Unknown. This is very obscure.
You can obtain the timezone with the JavaScript snippet
(new window.Intl.DateTimeFormat).resolvedOptions().timeZone
Furthermore, the scraperapi.com scrapers have no WebGL support. It is not possible to obtain the video card settings.
Usually, normal browsers have a video card such as:
"videoCard": [
"Intel Inc.",
"Intel Iris OpenGL Engine"
]
You can obtain your video card brand names with the following script:
(function getVideoCardInfo() {
const gl = document.createElement('canvas').getContext('webgl');
if (!gl) {
return {
error: "no webgl",
};
}
const debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
if(debugInfo){
return {
vendor: gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL),
renderer: gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL),
};
}
return {
error: "no WEBGL_debug_renderer_info",
};
})()
Furthermore, their scrapers advertise that they don't have any multimedia devices attached to it:
"multimediaDevices": {
"speakers": 0,
"micros": 0,
"webcams": 0
}
Another strange thing are the screen dimensions:
{
"outerWidth": 1440,
"outerHeight": 800,
"innerWidth": 800,
"innerHeight": 600,
}
Having a inner screen width x height of 800x600 is not prohibited, it is just very uncommon with real devices. But it is very common with default puppeteer chromium browsers...Just saying.
Detecting scrapingrobot.com
When scraping with scrapingrobot.com five times, we obtain the following fingerprints:
| # | user agent | browser fingerprint | ja3 fingerprint | canvas fingerprint |
|---|---|---|---|---|
| 1 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 | a265019e42a330492b5182c3a7275db9 | 66918128f1b9b03303d77c6f2eefd128 | 4EDA6E5B |
| 2 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15 | 9e945fadfdea5733f328c54542afb842 | 66918128f1b9b03303d77c6f2eefd128 | 4EDA6E5B |
| 3 | Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36 | eae9223cec3ad4985340f60fcb5f7e1f | - | 4EDA6E5B |
| 4 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.41 YaBrowser/21.2.0.1122 Yowser/2.5 Safari/537.36 | 310f1133a18911b800f465e6f783c7b2 | 66918128f1b9b03303d77c6f2eefd128 | 4EDA6E5B |
| 5 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36 | c877493938932c04567b0f967507f56d | - | 4EDA6E5B |
As you can see, the browser fingerprint switches all the time. This is a good sign and prevents the easiest route of detection. Regarding fingerprinting, I don't see too many issues with scrapingrobot.com.
However, there are some other issues with scrapingrobot.com:
The scrapers of scrapingrobot are using the following screen size properties:
"dimensions": {
"window.outerWidth": 800,
"window.outerHeight": 600,
"window.innerWidth": 2470,
"window.innerHeight": 1340,
"window.screen.width": 2560,
"window.screen.height": 1440
}
It should not be the case that the window.outerWidth and window.outerHeight properties are smaller than
the window.innerWidth and window.innerWidth screen dimensions. This is a very strong indication
that the browser was messed with.
Furthermore, their scrapers don't have any plugin information (navigator.plugins) associated with them. This is very uncommon for legit Chrome browses. Usually, every Chrome browser has standard plugin information such as
"plugins": [
{
"name": "Chrome PDF Plugin",
"description": "Portable Document Format",
"mimeType": {
"type": "application/x-google-chrome-pdf",
"suffixes": "pdf"
}
},
{
"name": "Chrome PDF Viewer",
"description": "",
"mimeType": {
"type": "application/pdf",
"suffixes": "pdf"
}
},
{
"name": "Native Client",
"description": "",
"mimeType": {
"type": "application/x-nacl",
"suffixes": ""
}
}
]
With scrapingrobot.com, this information looks like this:
"plugins": [
{
"mimeType": null
},
{
"mimeType": null
}
]
Another issue with the scrapers of scrapingrobot.com is that they don't have any multimedia devices (navigator.mediaDevices) associated with the browser. Usually, a normal browser has at least one multimedia device associated (such as speakers, micros, webcams).
Normal:
"multimediaDevices": {
"speakers": 1,
"micros": 1,
"webcams": 1
}
scrapingrobot.com:
"multimediaDevices": {
"speakers": 0,
"micros": 0,
"webcams": 0
}
Detecting scrapfly.io
The fingerprints recorded are as follows:
| # | user agent | browser fingerprint | ja3 fingerprint | TCP/IP fingerprint | canvas fingerprint | WebGL fingerprint |
|---|---|---|---|---|---|---|
| 1 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 | 75957d6c70a68c4d716e986554e313d4 | b32309a26951912be7dba376398abc3b | Linux / Chrome OS | 4EDA6E5B | 45b0cf9d |
| 2 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 | 210181aae7512e1e68c4058fa330c040 | b32309a26951912be7dba376398abc3b | Linux / Chrome OS | 4EDA6E5B | 45b0cf9d |
| 3 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 | 2c901d174dc4faf1b3c7e71e7a963d62 | b32309a26951912be7dba376398abc3b | Linux / Chrome OS | 4EDA6E5B | 45b0cf9d |
| 4 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 | a841a8e49dca94195ad161674c9762fa | 7f805430de1e7d98b1de033adb58cf46 | Linux / Chrome OS | 4EDA6E5B | 45b0cf9d |
| 5 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 | 52d35b65383ae737bd6d735078d59b20 | b32309a26951912be7dba376398abc3b | Linux / Chrome OS | 4EDA6E5B | 45b0cf9d |
Based on the fingerprints, we cannot state much. The browser fingerprint is different for every collected sample. This is already a good sign.
Maybe it is noteworthy to state that the TCP/IP fingerprint is releatively likely from an Linux based operating system and not from an Mac OS operating system as their User-Agent claims to be.
The canvas and WebGL fingerprint are always the same. Those fingerprints don't convey much entropy, hence it is not easy to say that the samples are all conducted from the same scraping software.
They seem to have created a overall good service. Unfortunately, they made some mistakes regarding the navigator property.
The User-Agent in the http headers is not the same as the user agent in the navigator property:
- HTTP User-Agent: Mozilla/5.0 (X11; Linux x86_64; x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36
navigatorUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
This is a very obvious mistake and this would result in a ban immediately with many anti bot systems.
Furthermore, they always spoof the same graphic card:
"videoCard": [
"Google Inc.",
"ANGLE (NVIDIA GeForce GTX 660 Direct3D9Ex vs_3_0 ps_3_0)"
],
Every browser they use has the same string ANGLE (NVIDIA GeForce GTX 660 Direct3D9Ex vs_3_0 ps_3_0) as their video card name.
Another issue is that their scraping browser does not have a single multimedia device attached to it:
"multimediaDevices": {
"speakers": 0,
"micros": 0,
"webcams": 0
},
Did you ever come accross a Macintosh Computer without micro, speaker or webcam? Nope, I haven't.
Another mistake they make is to not set the navigator.plugins property at all:
"plugins": [],
"mimeTypes": [],
Real browsers always have some standard values here.
Another issue with scrapfly.io is that all their HTTP requests come equipped with the X-Amzn-Trace-Id HTTP header set by all outgoing http requests originating from Amazon AWS. This feature allows to trace http sessions for debugging reasons.