Introduction
Without ever having developed a fully functional anti bot system myself, I want to investigate some of the obstacles that need to be overcome if I started such a project.
First of all, I have to define the functional specification that such an anti bot system must meet:
A bot detection system should be able to detect passively (1) that a website visitor (2) is in fact not a human but an automated program (3)
I deliberately keep my definition very broad.
- An automated program is software not controlled by an human user. Some examples:
- The Google Chrome browser automated with a framework such as playwright or puppeteer
- Simple
curlcommands orchestrated with shell scripts - Real physical mobile phones running Android automated over
adb(Android Debug Bridge) and (optionally) controlled with frameworks such as appium.io or stf (DeviceFarmer)
- Likewise, detecting passively means: Without actively interrupting the user's (or bot's) browser session by asking to solve a challenge task such as Google's reCAPTCHA or the newer hCAPTCHA. Put differently: The decision whether a website visitor is a human or a bot has to be made by passively observing signals such as TCP/IP streams and other data sent from the browser via JavaScript.
- And what means website visitor? There is a fundamental difference between a website visitor that simply opens a single page before leaving again and a user that performs a complex action such as logging into an online bank and transferring money. In the latter case, a bot detection system has much more time in order to detect a bot. Furthermore, in the latter case, there is also behavioral and intent data, which is completely lacking in the former case.
Our attacker model is as follows:
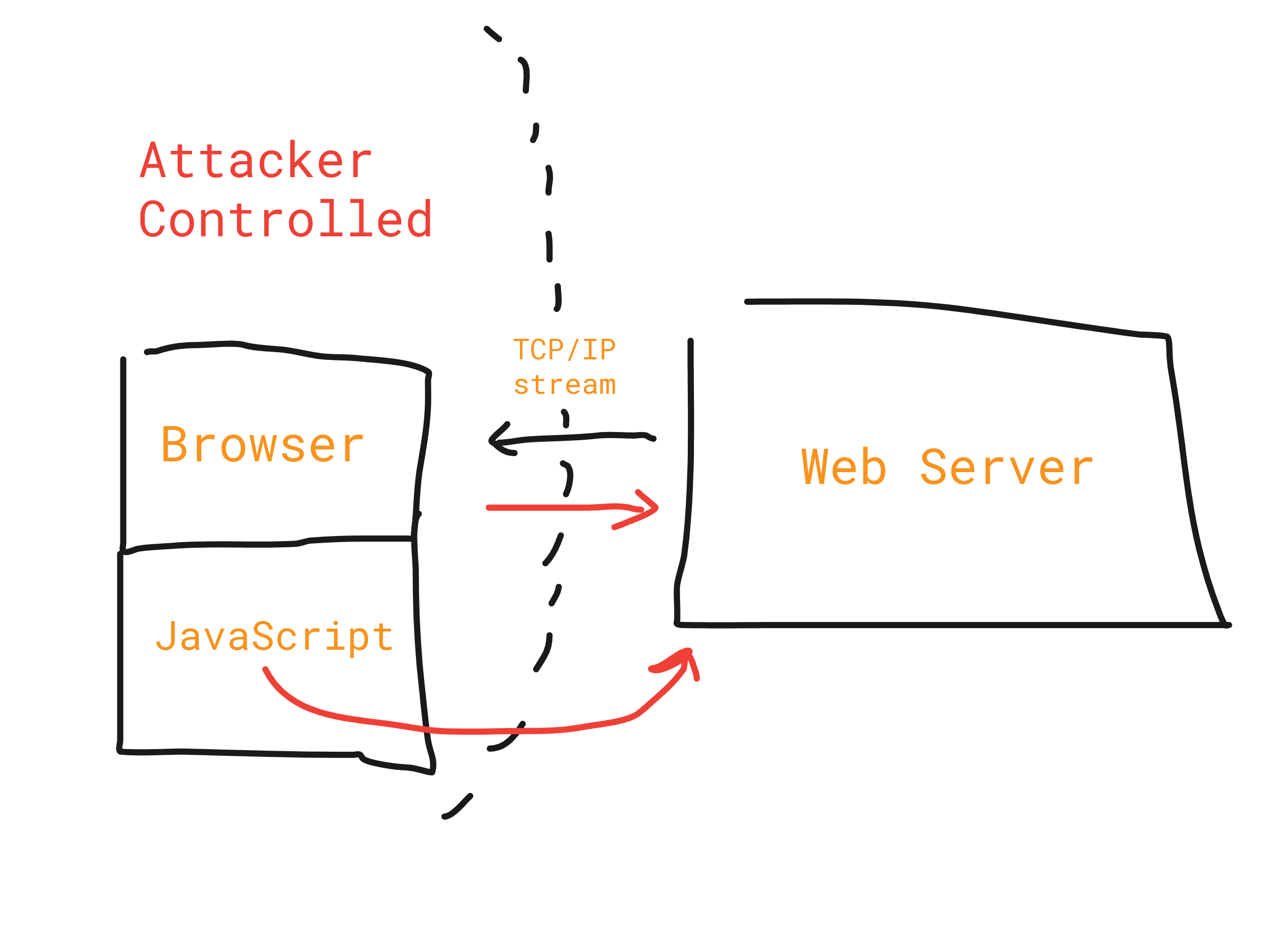
Some explanatory words regarding the graphic above:
Websites are served by web servers. Every message that the browser (client) sends to the web server has to be considered as potentially spoofed and tainted. This includes network messages created by JavaScript that are dynamically sent over WebSockets or the sendBeacon API. This is also the reason why in the traffic arrows from the browser to the web server are in red color.
A fundamental property of client/server security is: All input from clients cannot be trusted from the standpoint of the server. This will be important in the remainder of this blog post, that's why I repeat it so vehemently here.
So what are actually some methods to passively detect that a browser is not controlled by an organic human?
Actually there rarely exist signals that fall into that exact binary category of: This visitor is a bot or not.
Rather, anti bot vendors rephrase the question to: On what level can we uniquely identify a browser user and then rate limit her? Because that's the overall goal of anti bot systems: Rate limiting unique users.
Some techniques to identify users:
- By IP address
- By TLS or TCP/IP fingerprint
- By HTTP headers and their order/case sensitivity
- By browser fingerprints obtained via JavaScript (Including WebGL fingerprints, audio fingerprints, Picasso)
- By Cookies/Session ids
It should be obvious that the examples from the list above fall into two categories:
- Signals that are unspoofable due to the design of the Internet, such as IP addresses
- Data that clients send to the server, usually via JavaScript, which can be altered by clients at will
Of course an attacker can alter her IP address by setting up a proxy server.
Technically, spoofing IP addresses on a IP level will work, but the first router outside your home network will most likely drop the IP packet if it detects that the source IP does not belong to the correct network. And even if that does not happen: How are you ever going to receive a reply to your spoofed IP packet?
With TLS and TCP/IP fingerprinting, it's way easier to spoof those signals on the client side.
On the other hand, all the data that is collected via JavaScript can be spoofed by the client! Usually, anti bot companies collect a wide range of different data with JavaScript:
- Fingerprinting data mostly from the
navigatorproperty - Behavioral data such as mouse movements and touch events or key presses
- WebGL fingerprints or audio fingerprints
Architecture of Bot Detection Services
Let's think about how bot detection services are implemented by following a typical browsing session of a user visiting a website. As discussed above, bot detection systems collect data from both the client side and the server side. In the following section, I will follow a typical browsing session on a very low level and I will explain the different checks that a bot detection system performs at each point along the way.
The very first event relevant for bot detection is the DNS lookup of the hostname to which a browser establishes a connection. The browser uses the operating systems local DNS resolver to lookup the A and AAAA DNS resource record of a hostname. Worded differently, it asks for the IPv4 or IPv6 address that corresponds to the hostname used in the URL that was entered in the browser's address bar. The DNS request will be answered by the responsible name server.
During such a lookup, the DNS server can check that the resolvers client's IP address is the same or belongs to the same ISP as the IP address that communicates with the web server. Put differently, on the DNS server it can be checked that no DNS leak happens. A DNS leak occurs, if the DNS traffic is not routed through the proxy/VPN configured in the browser.
After the IP address of the domain name has been obtained, the browser is ready to establish a connection with the web server.
Before a browser is able to display anything, a TCP and TLS handshake has to occur to establish a TCP connection to the web server (In case we are using a https connection, which almost always is the case nowadays).

As soon as the first incoming SYN packet arrives on the web server, an anti bot system is capable of performing the following lookups on the server side:
-
Obtain the source IP address of the client. As soon as we have the source IP address, we can do a wide range of IP reputation checks:
- IP address counter: Check if we already have received too many requests from this specific IP address in a certain time frame. Abort the TCP handshake by sending a RST packet if that's the case.
- Also increase the counter for the specific (assumed) subnet to which this IP address belongs. Many attackers are in possession of whole IPv4 and IPv6 subnets to which this IP address belongs, this fact needs to be addressed.
- Lookup the IP address on spam abuse databases such as spamhaus.org. Are there any databases that indicate that this IP address was used for spamming/botting purposes?
- Conduct a datacenter IP lookup for the IP address. If the IP address belongs to a datacenter, it's more likely that it's a bot compared to a residential IP address. Similarly, you can also check if an IP address belongs to a large residential ISP such as Comcast, AT&T or Deutsche Telekom.
- Look up the geographical location for this IP address. Is it a tier 1 country (rich countries in the west such as the United Kingdom or Switzerland)? Or is the country known for spamming/botting (Ukraine, Vietnam, Russia - nothing personal here)?
- Look up the ASN, organization or registry to which the IP address belongs. This can be done using the
whoiscommand. For example,whois 15.23.65.22. - Use IP address metadata services such as ipinfo.io or https://ip-api.com/ to infer more metadata for this IP address.
- Make a reverse lookup for an IP address with the
hostcommand. Example:host 80.185.115.25. If the hostname belongs to a trustworthy company, give it a better reputation. If it belongs to a untrustworthy organization, block it.
-
Generate a TCP/IP fingerprint from the SYN packet. A TCP/IP fingerprint gives us information about the assumed operating system of the client based on certain TCP and IP header fields/values such as TCP options header field. The TCP/IP fingerprint alone does not have enough entropy to reasonably exclude a client. However, when the inferred OS seems to be Linux system, then it's valid to raise the bot score, since most legit users do not use Linux. The TCP/IP fingerprint can be altered and spoofed by the client!
- Measure TCP/IP latencies and the RTT's of the exchanged packages. What's the throughput? Can we infer that the client used a WiFi network?
After the initial TCP/IP handshake is completed, the TLS handshake comes next. After the TLS handshake is completed, the server is able to compute a TLS handshake fingerprint.
I am not a specialist regarding TLS fingerprinting, but my guess is that a TLS fingerprint has slightly more entropy compared to a TCP/IP fingerprint and allows to differentiate between different TLS implementations and maybe operating systems. If that is the case, then at this point it would be already possible to see if there is a mismatch in TCP/IP fingerprint OS and TLS fingerprint OS. However, keep in mind that TLS and TCP/IP fingerprints can easily be forged on the client side.
After the TLS handshake has been established, the client sends an initial HTTP GET request to fetch the requested URL. Let's assume the client requests the index.html document. Based on this very first GET request, we can do a couple of things:
- Compute a HTTP fingerprint. What headers are sent with the client? In what order are they sent? Are the headers case sensitive?
- Do the HTTP headers contain typical proxy headers such as
var proxy_headers = ['Forwarded', 'Proxy-Authorization',
'X-Forwarded-For', 'Proxy-Authenticate',
'X-Requested-With', 'From',
'X-Real-Ip', 'Via', 'True-Client-Ip', 'Proxy_Connection'];
- Does the HTTP Referer look suspicious?
- Is the HTTP version not from a modern browser but from a non-browser library such as
curlor Pythonrequests?
If all checks pass until this point, the web server is going to serve the contents of the index.html document. After the index.html document has been downloaded, the browser parses the page and loads linked images, CSS and JavaScript files.
The executed JavaScript in turn dynamically fetches more content which results in more HTTP requests, WebSocket streams and other forms of networking requests.
At this point, the anti bot detection system is ready to serve it's JavaScript client library that collects signals from the browser side.
Bot Detection Techniques on the Client Side with JavaScript
As soon as JavaScript is executed on the browser, there are a lot of different techniques to harvest data that help to make a decision whether the client is a bot or not.
Keep in mind that the JavaScript execution environment is controlled by the client! So is the data that is sent back to the web server!
Bot detection companies use many different techniques to camouflage their JavaScript signals collection libraries:
- JavaScript obfuscation
- JavaScript virtual machines
- Encryption and encoding of payloads sent back to the server (only makes sense in combination with obfuscation/virtual machines)
Those three obfuscation techniques remind me a bit of the old days of reverse engineering. However, it's much much harder to protect JavaScript code than to protect x86 assembly.
There are some reasons for that:
- JavaScript is a interpreted high level language
- Obfuscated JavaScript must conform to the ECMAScript specification
- Obfuscated JavaScript will at some point also be in AST (Abstract Syntax Tree) representation
- The obfuscated JavaScript must be supported by many browsers and needs to be performant
A well known JavaScript obfuscation tool is javascript-obfuscator. A good JavaScript de-obfuscation tool is de4js.
Quick Interlude
For example, when I look for apartments on the German real estate search engine immobilienscout24.de, I am sometimes presented a bot detection challenge that performs a check passively in the background.
This is the heavily obfuscated JavaScript file that does the bot detection work in the background. I spent around 30 minutes trying to understand what it does, but honestly I could not figure out much without spending more time. I only know that the script performs some checks and sends the following payload back to the server, where p is a 30KB long base64 encoded binary blob:
{
"solution":{
"interrogation":{
"p":"h6R2UwMDY2NnRfZ18oNUBwVTJKVWtNZnFqc2ZndX5NaHZyOGpf...[truncated]",
"st":1626613924,
"sr":113884550,
"cr":994722218
},
"version":"stable"
},
"old_token":null,
"error":null,
"performance":{
"interrogation":1006
}
}
The next steps in reverse engineering would be to find out what exactly p contains. Look at the place in the obfuscated JavaScript where p becomes encrypted/encoded and dump the clear text contents. Then I know what data is sent and I can therefore spoof it.
I am heavily assuming that the above JavaScript is Imperva's bot detection client side solution.
Before I dive deeper into some of the JavaScript bot detection techniques, I want to explain why collecting signals passively with JavaScript and stopping bots is so difficult. Assuming the bot detection execution time for the script is 200ms and then the data is transmitted in 50ms to the web server, which in turn has to make an API request to the central bot detection API (again 50ms), 300ms already passed before the client can be banned.
This means that all signals recorded by JavaScript that are sent to the bot detection API incur a large delay before a decision can be made on the server side.
This is also the reason why many bot detection companies decide upfront to interrupt the browsing session of the user and display a message that an active bot detection check is happening. Cloudflare Bot Management does this for example.
However, in this blog article I focus on passive detection without interrupting the user's workflow.
What if our goal is to only scrape a single page? Then an attacker can simply abort the execution of said script. Maybe the server then remembers: Hey, this specific client with IP XYZ never actually sent a JavaScript payload back home. Looks unusual: One of the following cases had to happen:
- There was a network outage
- The user navigated away before the JavaScript payload could be sent home
- The system / browser crashed
- The user blocked the execution of the script deliberately to evade bot detection
Only the last point indicates malicious behavior of the client. Therefore, every bot detection system needs to give each client some free attempts, let's say the IP address get blocked if a threshold of N=20 has surpassed.
But what if the user switches his IP address between requests? For example by using a mobile 4G or 5G proxy that sits between a Carrier-grade NAT?
You can't just block a whole mobile address range because you feel like it. Wikipedia says:
In cases of banning traffic based on IP addresses, the system might block the traffic of a spamming user by banning the user's IP address. If that user happens to be behind carrier-grade NAT, other users sharing the same public address with the spammer will be mistakenly blocked. This can create serious problems for forum and wiki administrators attempting to address disruptive actions from a single user sharing an IP address with legitimate users.
What I describe above is something very fundamental about bot detection systems: They must provide basic functionality without relying on JavaScript signals. Not only because every network message originating from the client is potentially spoofed, but also because some browsers simply cannot execute JavaScript or fail in the process of doing so! Some users don't have JavaScript enabled. Banning the IP address only because the client disabled JavaScript is too aggressive.
And there is another very important point here: Bot detection systems can only reliably ban clients by IP address! This is so important to understand. Every other signal from the client can be spoofed (if the client understands what he executes on his machine)!
If a bot detection system bans based on other ways of identification (Browser fingerprint, WebGL fingerprint, font fingerprint, TLS Fingerprint, TCP/IP fingerprint, ...), a client can change those fingerprints and evade a ban!
Having said that, let's look at some techniques to detect bots on the client side:
- Browser Fingerprinting with JavaScript is a very popular method. The idea is to collect as much browser entropy such as
navigator.languagesornavigator.platformas possible, while simultaneously trying to look for attributes that are static and don't change on browser/OS updates. - Proof of work challenges such as solving cryptographic puzzles in the browser as for example friendlycaptcha.com is doing it. The rough idea is: Make the browser find the input for a hash function until the first
Kbits are all zeroes. This takes some time. - Another common bot detection method is to produce unique fingerprints with the browser built in webGL rendering system that accesses the client's graphic hardware. For example, Google Picasso detects the client's operating system class by leveraging the unique outputs of the webGL renderer. They deliberately only want to reliably detect the device/operating system, simply because most spammers/botters use cheap cloud/hosting infrastructure which are mostly Linux flavors.
- JavaScript can be used to port scan the client's internal network. This allows to find out if certain suspicious well known ports are open, such as the one for the remote debugging protocol (9222) or the one for
adb(5037). Furthermore, this also allows to check if the client has a router accessible by scanning for192.168.1.1. - Recording behavioral data by listening to DOM events such as
onmousemove,onscroll,onkeydown. - Then there exist a wide range of techniques to detect automation frameworks such as puppeteer or playwright or mismatches in the browser JavaScript environment which indicate that the browser was messed with. creep.js is probably one of the best tools out there for that purpose.
- Lastly, the technique that is still most used is the good old CAPTCHA. Google's reCAPTCHA or the newer hCAPTCHA are well known solutions.
- In general, JavaScript allows bot detection services to collect and ENORMOUS amount of data from browsers. JavaScript leaks so much information, it's unfathomable. Just to throw some words into the mix: Browser red pills, WebRTC leaks, scanning the internal network...
The Proof of Work kind of challenges cannot be bypassed by clients. They have to be solved somewhere. However, the solving of the proof of work challenge does not have to be on the browser/client that receives the challenge.
Crypto proof of work challenges can be solved by dedicated hardware for cryptography, it does not need to be solved by the browser. This speeds up things considerably. I would guess that solving crypto hashing challenges on dedicated hardware is between 20 to 200 times faster than with JavaScript.
Solving captchas such as Google's reCAPTCHA can be outsourced to captcha solving services, such as for example deathbycaptcha.com or 2captcha.com.
Even solving more complex challenges such as Google Picasso can be pre-computed. All what you need is a network of different devices and access to a browser with JavaScript enabled. If you have a website with 10k unique visitors per month, you probably will be fine.
Conclusion
Bot detection systems consists of IP reputation techniques and client side data gathering scripts. They need to reliably work even if their client side JavaScript libraries send spoofed data.
Because of that potential spoofing, bot detection JavaScript libraries are heavily obfuscated to make it harder for attackers to understand how they work. Proof of work challenges do not have to be solved by the client that received the challenge - they can be outsourced.
There are two fundamental approaches how to defeat bot detection:
- Don't participate in the cat and mouse race between bot detection companies and botters and use real devices with legit IP addresses (such as mobile device farms) to conduct your attacks. This is very costly in terms of hardware and data plans.
- Use cheap AWS cloud infrastructure and high reputation proxies and then spoof the JavaScript payload from the bot detection JavaScript in order to appear legit. This requires a very high understanding of JavaScript and reverse engineering and is thus very costly regarding time and expertise.
Only one thing is for sure: All what bot detection companies are doing is rising the transaction costs for automation in the Internet. But we live in times were platforms are becoming more monopolized and powerful each passing day.
At the same time, mobile phones become cheaper and cheaper. In our modern times, a mobile phone basically constitutes a digital identity. But all what you need to acquire such an identity is 100USD to buy a cheap phone and a cheap data plan for 7.99USD a month. If bot detection companies do their job too good, spammers will simply create mobile device farms and conduct their botting/spamming/attacks with those device farms.
Detecting real automated mobile devices is much much harder then to detect Headless Chrome on AWS...As of now, I would only know two ways to detect such a mobile device farm:
- Portscan for an open
adbport with JavaScript - Check the Javascript Accelerometer API and Gyroscope. Zero-movement velocity and rotation data is quite suspicious for mobile phones.
- Maybe some statistical analysis that a website suddenly has a surge in traffic from cheap or old Android smartphones from the same CGNAT which might indicate a mobile device farm as source of the traffic...