For the past couple of years, I spent a lot of time creating web scrapers and information extraction tools for clients and my own service. Recently, I had an idea how I can improve the quality of results while spending less time on data extraction rules. The result of this work is the experimental javascript project struktur.js.
Web scraping is soul crushing work. There are mainly two reasons for that:
Reason 1: CSS Selectors and XPath queries are hard to maintain
Whenever the websites markup changes, you need to adapt your selectors. Furthermore, those selectors assume a static response from the scraped web server. If the structure changes slightly, the predefined CSS selectors fail miserably and the complete scrape job has to be restarted.
Many websites also have randomized class names and ID's in their HTML markup, such that those attributes carry no semantic information and cannot be used in CSS selectors. For example, this is html that google returns in their markup:
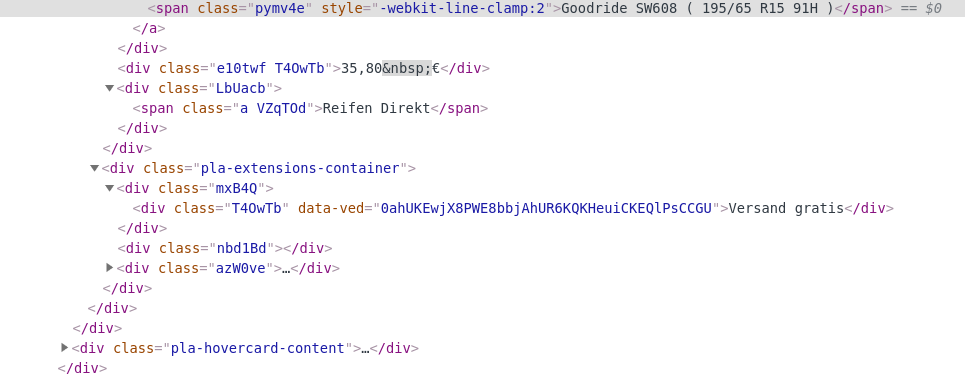
In our modern times, many websites are written in a Javascript frontend framework such as Angular or ReactJS. This increases the trend of class names with no semantic relation to its content.
I finally decided to think of an alternative ways of web scraping, when I had to commit the following code into se-scraper:
// parse right side product information
var right_side_info = {};
right_side_info.review = $('#rhs .cu-container g-review-stars span').attr('aria-label');
right_side_info.title = $('#rhs .cu-container g-review-stars').parent().find('div:first-child').text();
right_side_info.num_reviews = $('#rhs .cu-container g-review-stars').parent().find('div:nth-of-type(2)').text();
right_side_info.vendors = [];
right_side_info.info = $('#rhs_block > div > div > div > div:nth-child(5) > div > div').text();
$('#rhs .cu-container .rhsvw > div > div:nth-child(4) > div > div:nth-child(3) > div').each((i, element) => {
right_side_info.vendors.push({
price: $(element).find('span:nth-of-type(1)').text(),
merchant_name: $(element).find('span:nth-child(3) a:nth-child(2)').text(),
merchant_ad_link: $(element).find('span:nth-child(3) a:first-child').attr('href'),
merchant_link: $(element).find('span:nth-child(3) a:nth-child(2)').attr('href'),
source_name: $(element).find('span:nth-child(4) a').text(),
source_link: $(element).find('span:nth-child(4) a').attr('href'),
info: $(element).find('div span').text(),
shipping: $(element).find('span:last-child > span').text(),
})
});
This code is ugly and probably breaks in a couple of weeks. Then I need at least two hours of my time to fix it. I simply cannot do this for 10 different websites where I have to maintain a different set of scraping rules via CSS selectors.
Reason 2: Websites have built in defenses against web scraping
Of course it is reasonable to protect yourself against excessive and malicious scraping attempts. Nobody wants to have their whole body of data scraped by third parties. The reason is obvious: The worth of many providers is constituted by the richness of information they have. For example Linkedin's sole worth depends on the information monopoly about people in the business workforce. For this reason, they employ very strict defenses against large scale scraping.
Those defenses block clients based on
- IP addresses
- User agents and other HTTP headers
- whether the client has a javascript execution engine
- number of interactions on the site, mouse movements, swiping behavior, pauses
- whether the client has a previously known profile
- captchas
It all boils down to the question whether the client is a robot or human?. There is a large industry that tries to detect bots. Well known companies in this industry are Distil and Imperva. They try to distinguish bots and humans by using machine learning models using indicators such as mouse movements, swipe behavior on mobile apps, accelerometer statistics and device fingerprints. This topic has enough depth for another major blog post and will not be researched here any further.
Scraping without a single CSS selector - Detecting Structures
We cannot make much against web scraping defenses, since they are implemented on the server side. We can only invest more in resources such as IP addresses or proxies to obtain a larger scraping infrastructure.
In this blog post, we will tackle the first issue, the problem of reliably detecting relevant structure across websites without using XPath or CSS selectors. What exactly is coherent structure?
In the remainder of this article, we define relevant structure to be a collection of similar objects which are of interest to the user. And our task is to recognize this structure on every webpage in the Internet. It is a collection, if there are at least N objects with the same tagName under a container node. The objects are similar, if their visible content is similar. Of course this is a circular definition, because it is still an open question how to exactly measure it.
Examples of recurring structure
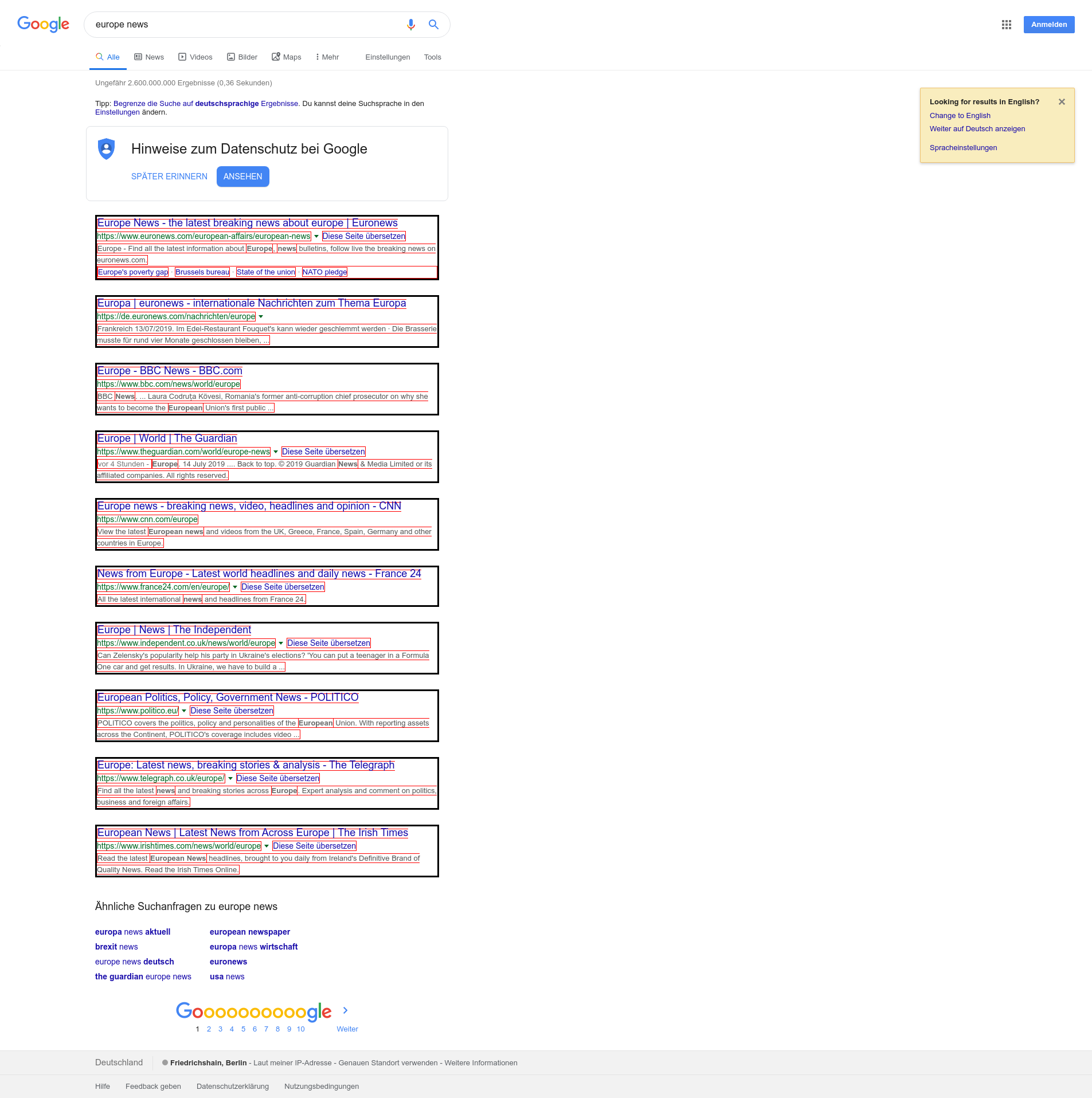
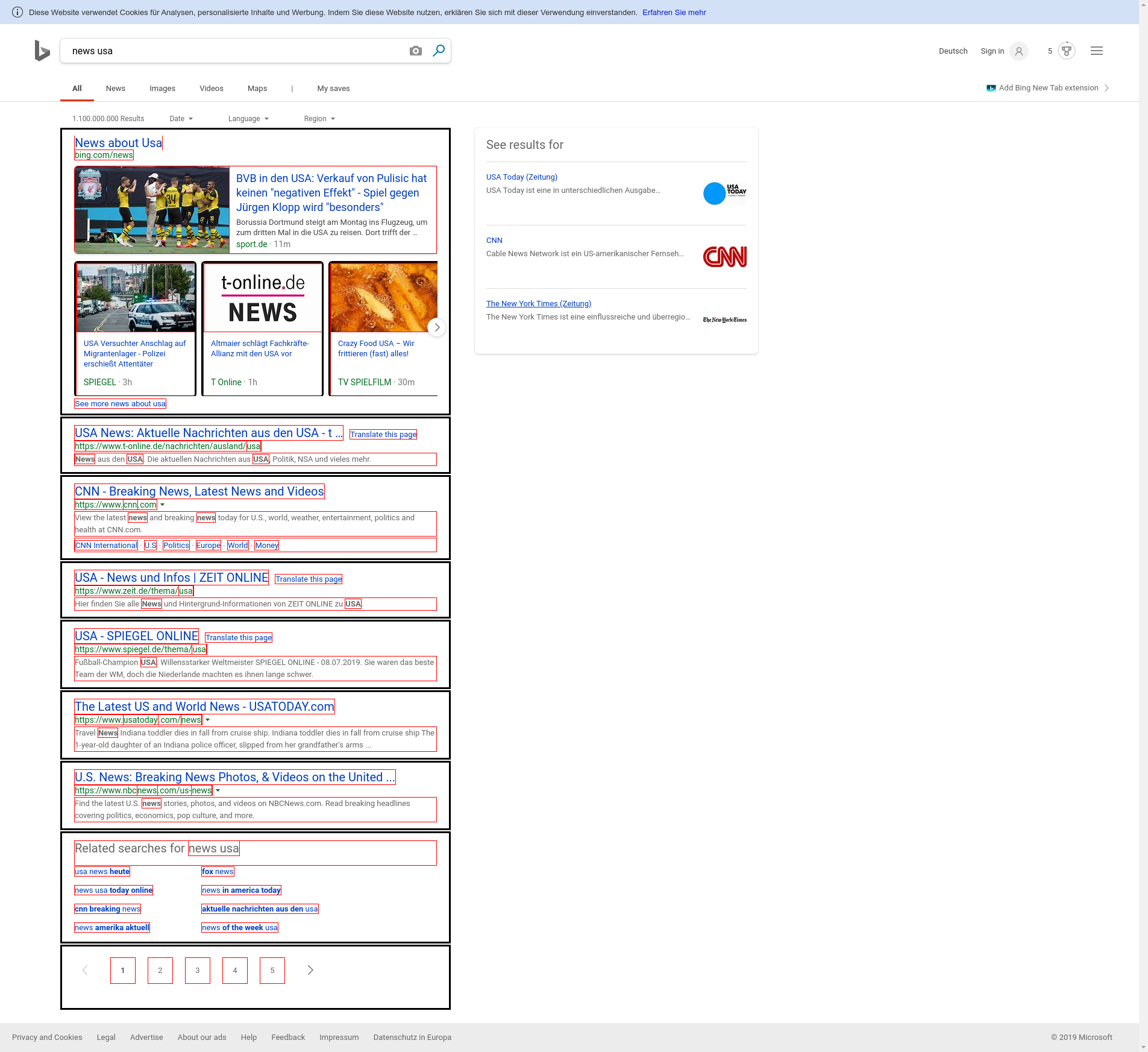
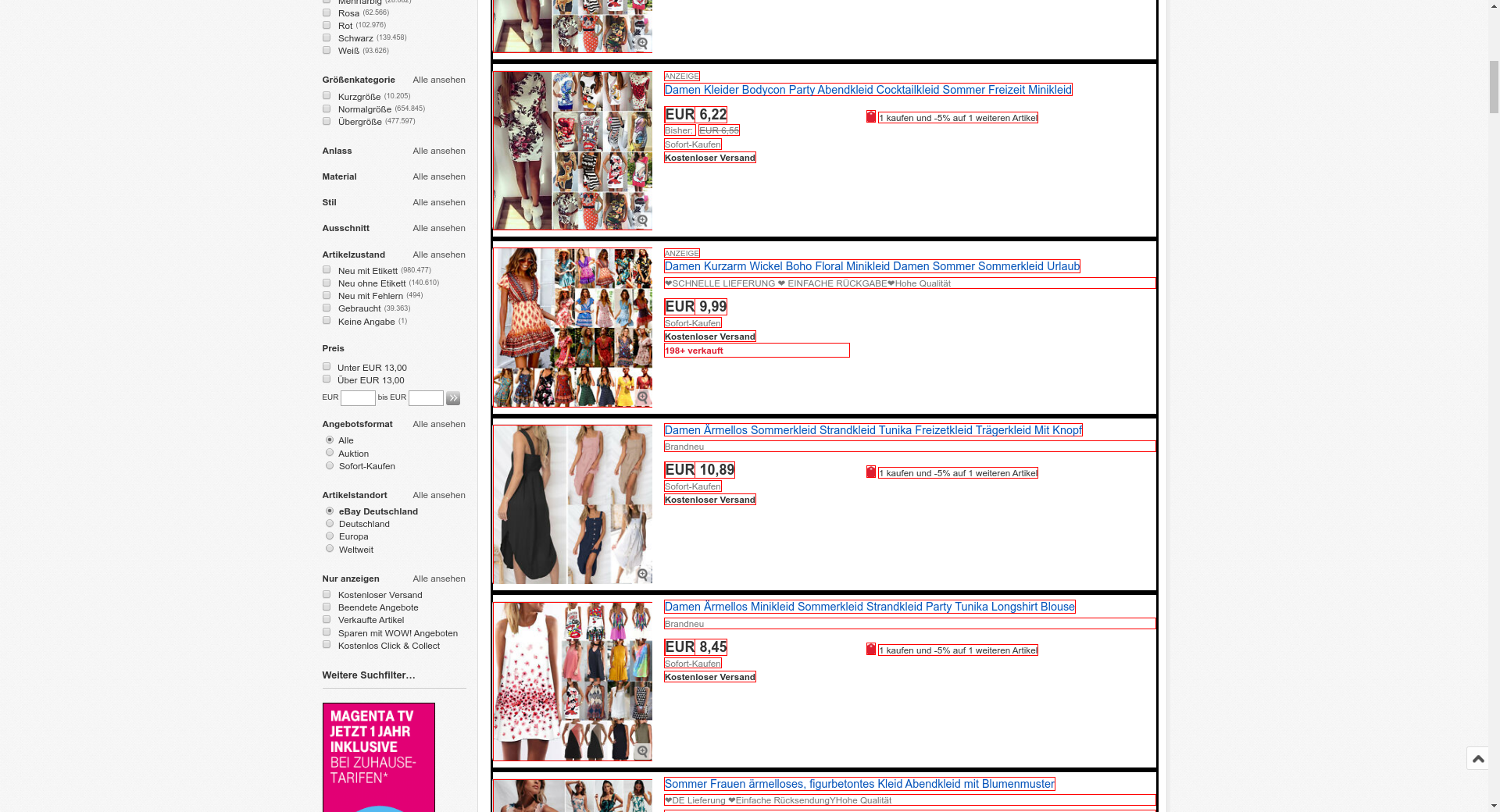
All those items have a common structure when interpreted visually: They have more or less the same vertical alignment, the same font size, the same html tag within the same hierarchy level.
The huge problem is that structure is created dynamically from the interplay of HTML, JavaScript and CSS. This means that the HTML structure does not necessarily need to resemble the visual output. Therefore we need to operate on a rendered web page. This implies that we need to scrape with real, headless browsers using libraries such as puppeteer.
What assumptions do we make?
The input is a website rendered by a modern browser with javascript support. We will use puppeteer to render websites and puppeteer-extra-plugin-stealth to appear like we use a real browser.
We assume that structure is what humans consider to be related structure.
- Reading goes from top-left to bottom-right
- Identical horizontal/vertical alignment among objects
- More or less same size of bounding rectangles of the object of interest
- As output we are merely interested in Links, Text and Images (which are Links). The output needs to be visible/displayed in the DOM.
- Only structure that takes a major part of the visible viewport is considered structure
- There must be at least N=6 objects within a container to be considered recurring structure
When websites protect themselves against web scraping on the HTML level, they need to present a website to the non malicious visitor at some point. And our approach is to extract this information at exactly the point after rendering.
Algorithm Description
In a first step, we find potential structure candidates:
Take a starting node as input. If no node is given, use the body element.
See if the element contains at least N identical elements (such as div, article, li, section, ...). If yes, mark those child nodes as potential structure candidates.
Visit the next node in the tree and check again for N identical elements.
After all candidates have been found, get the bonding boxes of the candidates with getBoundingClientRect() If the bounding boxes vertically and horizontally align, have more or less identical dimensions, and make up a significant part of document.body.getBoundingClientRect(), add those elements to the potential structures. There are further tests possible.
In a second step, we cross correlate the contents of the structure candidates and filter out objects that are not similar enough: We compare the items within the potential structures. If they share common characteristics, we consider those elements to form a valid structure. We are only interested in img, a and textNode. Furthermore, we consider only visible nodes.
Example: If we find 8 results in a google search, all those results essentially have a title (link with text), a visible link in green font (this is only green text and a child node of the title) and a snippet. The snippet typically consists of many different text nodes. Therefore one potential filter could be:
- Each object must have a link with text with font size
Xat the beginning of the object. - There must be a textNode with green font after this title.
- There must be some text after this green colored text.
Downsides
Because our algorithm is abstract, the JSON output cannot have reasonable variable names. The algorithm cannot know which text of the object is the title, which part is a price, what is a date, and so on. This means that a post data-extraction step is necessary to match variable names to the output.
Furthermore, we cannot reliably know the correct N that specifies how many recurring elements should be in a structure. It depends on the website.
Run struktur yourself
Enough talking, you can test struktur.js in the following way. First download struktur.js and put it in the same path as the following script:
// puppeteer-extra is a drop-in replacement for puppeteer,
// it augments the installed puppeteer with plugin functionality
const puppeteer = require("puppeteer-extra");
// add stealth plugin and use defaults (all evasion techniques)
const pluginStealth = require("puppeteer-extra-plugin-stealth");
puppeteer.use(pluginStealth());
const config = {
urls: {
'google': 'https://www.google.de/search?q=europe+news',
},
chrome_flags: [
'--disable-infobars',
'--window-position=0,0',
'--ignore-certifcate-errors',
'--ignore-certifcate-errors-spki-list',
'--window-size=1920,1040',
'--start-fullscreen',
'--hide-scrollbars',
'--disable-notifications',
],
};
puppeteer.launch({ headless: false, args: config.chrome_flags }).then(async browser => {
const page = await browser.newPage();
await page.setBypassCSP(true);
await page.setViewport({ width: 1920, height: 1040 });
await page.goto(config.urls.google, {waitUntil: 'networkidle0'});
await page.waitFor(1000);
await page.addScriptTag({path: 'struktur.js'});
var results = await page.evaluate(() => {
return struktur({
N: 7,
highlightStruktur: true,
highlightContent: true,
addClass: false,
});
});
await page.waitFor(1000);
console.log(results);
await browser.close();
});
Then install dependencies with
npm i
And run the above script with node. You will see the found structure of the google search made as JSON. You can specify any other website you want.